Accessing Toolbox Data
We have attempted to create a number of data capture options to suit varied purposes, extents of use and resources available. Our philosophy with the Early Years Toolbox is to enable these tools getting into the hands of those who have the greatest opportunity to inform and/or affect children’s trajectories. To achieve this, it means the tools have to be broadly usable, accessible, actionable and low-cost – in addition to usual requirements of rigorous validity and reliability standards. In relation to data capture, there are three options tailored to suit different purposes and users:
1. Scores on the final screen
2. E-mail data capture
3. Database data capture
1. Scores on Final Screen
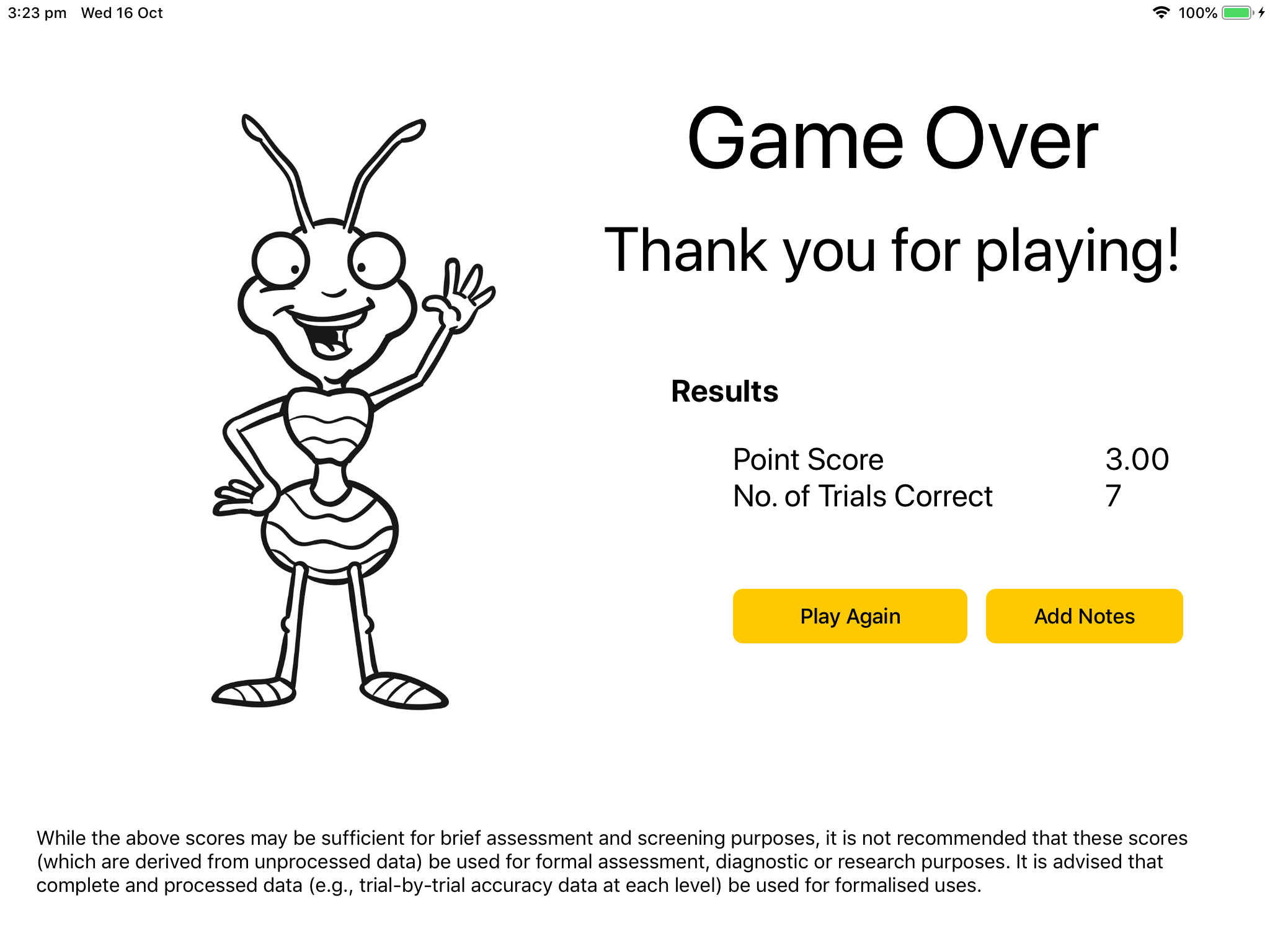
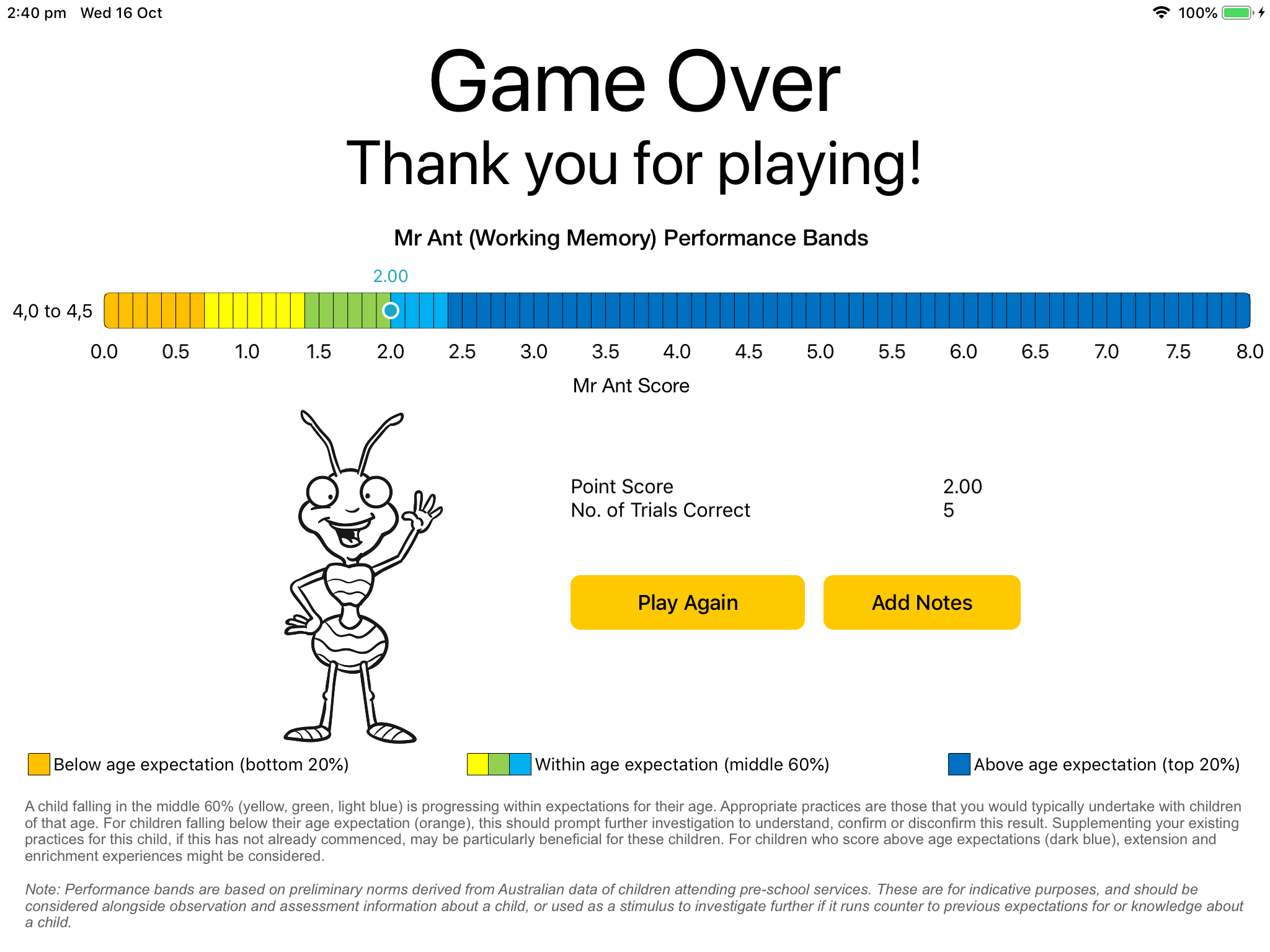
On completion of an EYT app, a summary of the results will be presented on the final screen – either with or without Child Performance Charts (depending on the app settings you selected). Both show summary scores based on the child’s trial-by-trial performance, but are not recommended for research applications. Instead, it is recommended that the e-mail or database options are used for research purposes, so trial-by-trial accuracy and response time data can be examined and collated in the desired manner. These final screen scores should nevertheless provide a good estimate of the child’s ability, assuming the integrity of the task’s administration and child’s engagement (see earlier training material).
The child performance charts, if selected, can be interpreted as follows: A score within the middle three bands (yellow, green, light blue) can roughly be considered within age expectations (characterising the middle 60% of children that age). A score in the dark blue can be considered above age expectations (the top 20% of children that age). Scores in the orange can be considered as somewhat below age expectations (the bottom 20% of children that age). Note: Performance bands are based on preliminary norms derived from Australian children attending pre-school services and thus are only for indicative purposes.
Add Notes: There is the opportunity to add notes in relation to this child/data by 'tapping the Add Notes button'. This will record notes to the database or e-mail, where those options have been selected.
Play Again: This will return you to the app’s home screen. All fields will be cleared, but the app’s settings will be retained in the settings menu.
Data and Results: Trial-by-trial accuracy and response time data have been captured by the iPad, and if either the e-mail or database option have been selected these data points will be sent to the identified location. If the iPad is connected to Wi-Fi during administration, these data will immediately be sent to the identified location. If not, these entries will queue on the iPad until the next time the iPad is connected and this app is launched. Note: This data file is generated at the final screen, so only completed tasks will generate a data file. If the task is not completed, it is not recommended that you use partial data (given it is unclear how far the child would have progressed if they had attempted to complete the task).
| Benefits + | Limitations - |
|---|---|
| Immediate | Based on unprocessed data, so is not recommended for research purposes |
| No setup required - provided by default |
|
| No associated costs |
Suggested Users: Educational uses where immediate information is privileged.
2. E-mail Data
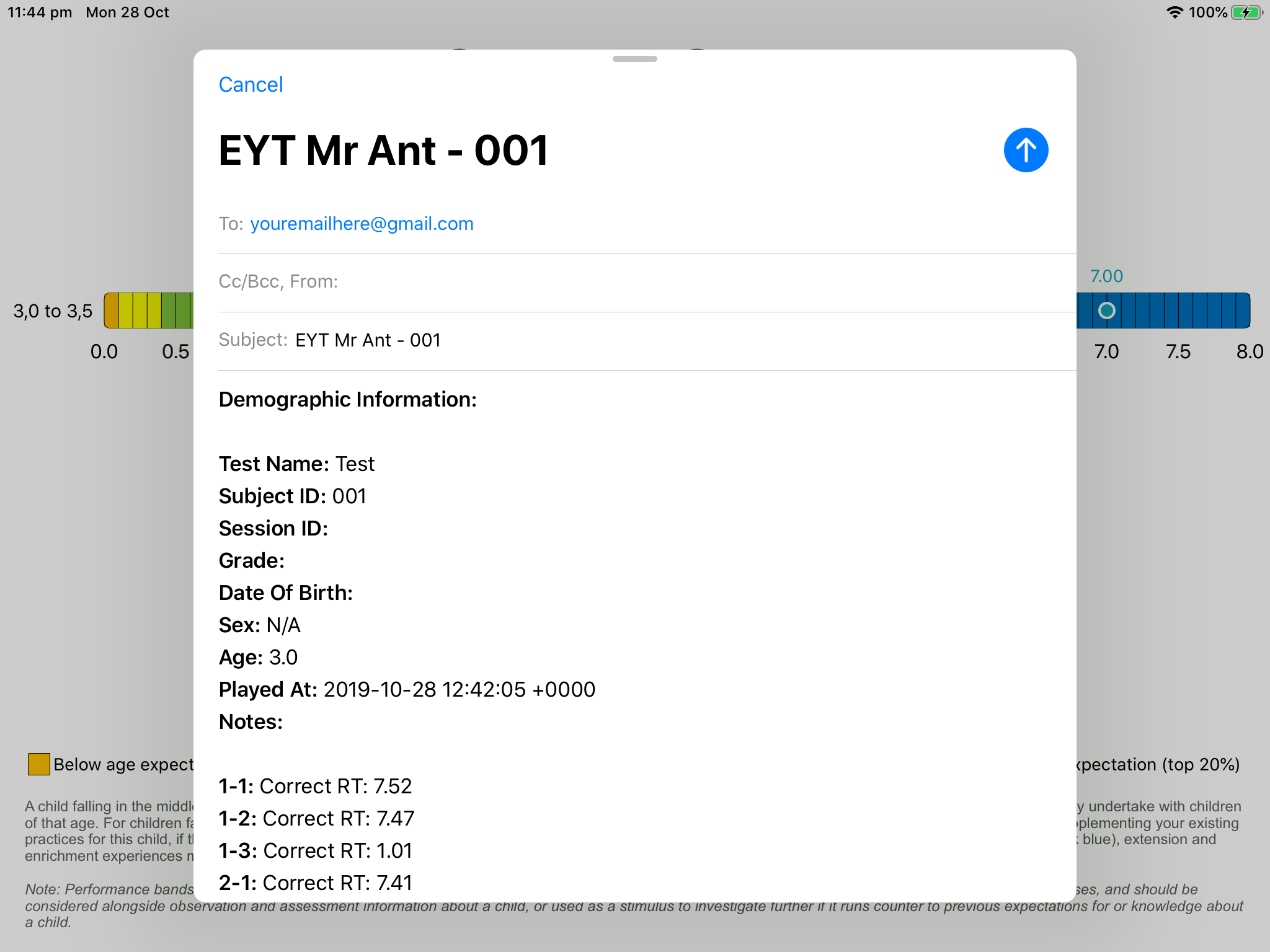
Trial-by-trial accuracy and response time data can be sent to any e-mail address, once specified in the settings menu. This uses the iPad’s Mail app, so this will also need to be set up. In this option, on the final screen a populated e-mail will pop up – just click send and it will be added to the Outbox of the iPad’s Mail app. Once connected to Wi-Fi, this e-mail will be sent to the specified e-mail address. This is an easy setup solution with no associated costs but does require some transfer of the e-mailed data into the data analysis software after collection. To make this easier, we provide free Excel data templates below into which these data can be entered, and will automatically process and score these data for you.
| Benefits + | Limitations - |
|---|---|
| Quick setup | Requires post-collection processing, to transfer e-mailed data into the desired software, processing of data, scoring, etc. |
| No associated costs |
Suggested Users: Smaller planned uses, in terms of number of children, EYT apps that will be used and/or single point in time.
Generating scores from e-mail data
While it is possible to simply use the summary statistics we provide on the end screen after each administration, note that these scores are derived from unprocessed data, and thus should be considered in this light. For larger-scale and more formalised uses, we recommend using full trial-by-trial data for analysis.

For the Mr Ant task, scores are calculated using a point score calculated as: beginning from level 1, one point for each consecutive level in which at least two of the three trials were performed accurately, plus 1/3 of a point for all correct trials thereafter. For a sample spreadsheet to facilitate this data cleaning process, please click here.

For the Not This task, scores are calculated using a point score calculated as: beginning from level 1, one point for each consecutive level in which at least three of the five trials were performed accurately, plus 1/5 of a point for all correct trials thereafter. For a sample spreadsheet to facilitate this data cleaning process, please click here.

For the Go/No-Go task, we start by removing all trials for which responding was faster than 300 ms (and thus is unlikely to have been in response to the stimulus). We then remove all blocks in which the child was largely non-responsive (go accuracy below 20% and no-go accuracy exceeds 80%) or indiscriminately responsive (go accuracy exceeds 80% and no-go accuracy below 20%). From the resultant data, we then calculate an impulse control score (% Go Accuracy x % No-Go Accuracy), which reflects the child’s ability to withhold their response in the context of the strength of that typical (pre-potent) response. For a sample spreadsheet to facilitate this data cleaning and calculation process, please click here.

For the Card Sorting task, we tend to review the accuracy of Block 1 (pre-switch) and Block 2 (post-switch). Since a post-switch accuracy score intends to index the extent to which a child could successfully switch from one sorting rule to the next, we swap the two scores if the post-switch accuracy is larger than the pre-switch accuracy. This ensures that final post-switch scores (Block 2 + Block 3) reflects the child’s ability to successfully switch between sorting rules. For a sample spreadsheet to facilitate this, please click here.

For the Child Self-Regulation and Behaviour Questionnaire, a number of items must be reverse-scored prior to combination into sub-scales. The following sub-scales can be derived as follows:
- Sociability: Items 1, 4, 9, 16(reversed), 22(reversed), 27, 32
- Externalising: Items 3, 20, 23, 26, 28
- Internalising: Items 17, 21, 25, 33, 34
- Prosocial: Items 15, 19, 24, 27, 30
- Behavioural Self-Regulation: Items 7(reversed), 13, 15, 29(reversed), 30, 31(reversed)
- Cognitive Self-Regulation: Items 5, 6, 8, 12, 18
- Emotional Self-Regulation: Items 2, 10, 11(reversed), 14(reversed), 23(reversed), 26(reversed)
For a sample spreadsheet to facilitate this data cleaning process, please click here.

For the Early Numeracy task, scores are calculated as the number of correct items. Skip rules start children at different points in the game based on their age, with credit given for those earlier items (unless the child fails on early items, in which case they are returned to skipped items). Stop rules end the game after 5 consecutive incorrect responses, with subsequent unattempted trials considered incorrect. For a sample spreadsheet to facilitate this data cleaning process, please click here.

For the PRSIST task, the following sub-scales are derived from observer ratings as follows:
- Cognitive Self-Regulation: Items 1, 2, 3, 4, 8 (or 9, depending on actvity)
- Behavioural Self-Regulation: Items 5, 6, 7
Ratings are completed for each activity separately (i.e., memory game, curiosity boxes) and combined into subscales as above. These activity scores are then averaged to generate overall PRSIST cognitive and behavioural self-regulation scores. For a sample spreadsheet to facilitate this data cleaning process, please click here.

For the Vocab task, scores are calculated as the number of correct items. Stop rules end the game after 6 consecutive incorrect responses, with subsequent unattempted trials considered incorrect. For a sample spreadsheet to facilitate this data cleaning process, please click here.
3. Online Database
For use with large numbers of children, use of numerous EYT apps and/or if apps will be used across multiple instances (e.g., studies, timepoints), an online database is often a more efficient solution; however, depending on your team’s level of web programming proficiency, it may require some resource. That is, with this option you can use the code we developed for our own database (what we routinely use) to create your own, to which the data are automatically sent after task completion. The online database allows you to allocate data to different studies, create users with permissions to view only particular app/study data, and extract the data into a .csv file that collates the data and provides raw data and summary scores after processing. This eliminates the need for transfer of data from e-mail to spreadsheet and eliminates need to do your own data processing and scoring (although the raw data are provided if you would like to). If you are sufficiently savvy at coding, we can share the code with you at no cost so you can set up your own database. E-mail A/Prof Steven Howard at [email protected] for access. If you are not a coder yourself (as we are not), we can put you in touch with our external developers who can assist in setting this up for you (at their hourly rate). This would be a one-off cost, although they also have low-cost plans if you would like them to take care of the database hosting for you as well. If you are interested in this assistance, you can contact A/Prof Steven Howard at [email protected] or Sophia Lay at [email protected].
| Benefits + | Limitations - |
|---|---|
| Data is quickly and easily collated and extracted | Requires a compatible database that is designed to accept EYT data |
| Data are automatically sent to the database when connected to Wi-Fi, or queued on the iPad until the next time the iPad is connected and the app is launched. |
Likely to involve some cost.
Note that we collect no proceeds from any of this, and contribute our time for free in spirit of dissemination
|
| Easy setup in the app |
|
| Backup files stored on the iPad as the fail-safe to ensure no data loss |
|
| Does not require an internet connection to collect data |
Suggested Users: Larger planned uses, in terms of number of children, EYT apps that will be used and/or repeated use over time.
Note: The database has been created to capture, aggregate and export data of Early Years Toolbox apps in their validated form. As such, we highly recommend use of the tools in their validated form, and cannot ensure that the database would be able to capture (without error) any and all manipulations to the apps. For instance, for the go/no-go task, the database can capture and export configurations that use the validated number of trials (75), blocks (3) and ratio of go:no-go trials (80%). It can also handle configurations where the number of trials within a block or the total number of blocks is lower than this; however, it is not currently configured to handle permutations whereby trials per block or blocks exceed this number.
Fail Safes
As researchers ourselves, we understand the importance of ensuring no data is lost. For this reason we
have implemented a number of fail safes to assist in data management.
1) Each app's settings menu has a 'Last Data Sync' time stamp so you can quickly and easily see
whether the data has been submitted to the specified database;
2) When database or e-mail logging is enabled, the iPad also keeps local logs of the data
files that can be manually extracted in the unusual case that they do not submit to the database. As long as
the app is not deleted, these logs remain accessible through iTunes. Please click here for a
step-by-step guide to manual data extraction.